Splunk Archiver
Simplify the management of your Splunk data with Conducive's Splunk Archiver. Starting at $2,995.


Why does required disk space increase exponentially?
- Splunk’s default archiving solution doesn’t remove redundant data from buckets or duplicate buckets from a cluster. Splunk freezes all of your data, even though that isn’t necessary.
- With the following calculation, you can see how easily a 1TB license in a clustered environment (replication factor of 3) can require at least 1 Petabyte of storage every year.
1TB Per Day X 3 (replication factor) X 365 = 1,095 TB per year = 1.095 Petabytes.

Does the Archiver fix this?
Conducive’s Archiver for Splunk removes redundant data and eliminates duplicate buckets.
Our customers are seeing an average of 80% reduction in storage space per bucket by removing redundant data and an additional 66% reduction by removing duplicate buckets.
For a 1TB license, your annual long-term storage requirement should require less than 100TB per year–a 90% reduction from 1.095 Petabytes.
Can you do this without Conducive's Archiver?
You could modify Splunk’s default script to remove redundant data, but that won’t eliminate duplicate buckets. Also, when you remove the redundant data, you will not be able to track the contents of each bucket when you need to restore data.
You will realize that it's nearly impossible to restore frozen data.

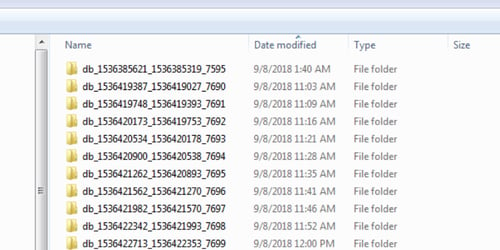
Why is it difficult to restore data?
- Splunk’s built-in archiving solution copies frozen buckets to a directory of your choice and leaves everything else up to you. Splunk doesn’t track frozen buckets or help you restore them. You have to manage the storage space, and you have to find the buckets when you want to restore them.
- A 1TB-per-day clustered environment will create a minimum of 150-300 buckets per day. For 1TB, Splunk will create 36,000-120,000 buckets per year, and in many cases more than that. When you need to restore data, you have to search through each of these buckets (represented as a folder or directory on your file system) to locate the data you want to restore. You also have to ensure you only restore one copy of each bucket. Restoring duplicate buckets could create duplicate search results. Done manually, this could take weeks. Of course, it's possible to write a script to identify some of the data, but that requires time and skills.
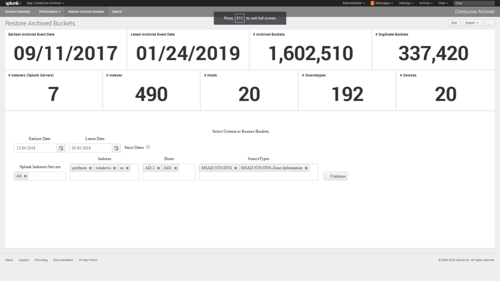
How does Conducive's Archiver make restoring data easy?
To easily restore frozen data, Conducive’s Archiver tracks all of the details of each bucket, allowing you to restore by host, sourcetype, index, and data range—all with the click of a button.
No more searching through thousands or millions of directories to find the data you want to restore. No more ensuring duplicate buckets aren’t restored. No more hassle. Restore your frozen data with the click of a button.
Restore Splunk Frozen Data
“We started off using Splunk’s built-in mechanism to freeze/archive our compliance data. What we didn’t realize at the time was how difficult it would be to restore that data.
Our auditors requested that we go through an exercise to prove we could restore data for a specific time period across specific hosts. That’s when we discovered we had millions of frozen archive files in the S3 archive. Because the entire archive was multiple terabytes of data, we we knew we didn’t have enough disk space to restore all of it, which would have been the easy solution. Our goal was to restore the subset of frozen files requested by the auditors, but we calculated it would take at least 6 person-days to identify the files we needed to restore.
We started searching the web for a solution when we found Conducive and their Archiver for Splunk. Using Conducive’s Archiver we were able to scan and catalog our existing archive, allowing us to restore the exact data requested by the auditors, all in less than 1 day.
We’re now using the Archiver to both manage frozen data archiving, as well as using it to provide reports to the auditors and restore the data as requested. We can do all of this from a UI that lets us choose the date ranges, sourcetypes, indexes and hosts to restore. The entire process usually only takes a few minutes of time.”
The Old Way
The New Way
One-Click Restore
- Restore frozen data based on time range, host, sourcetype, and index.
- Archiver retrieves selected data from storage with the click of a button.
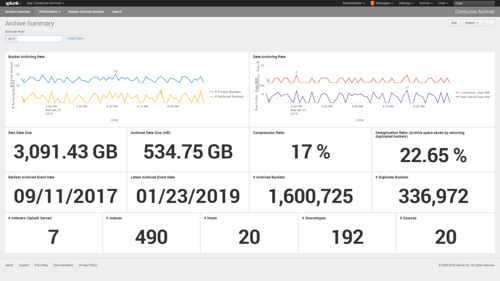
Managed Archival Process
- Ensure that your frozen data is properly archived.
- Easily create reports for your auditors.
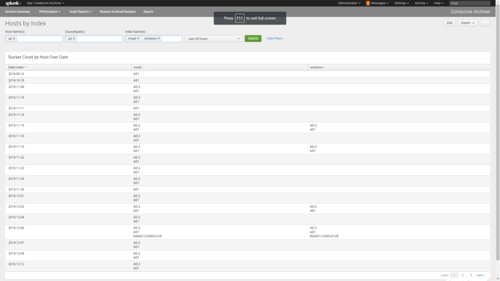
Reporting
- Provide auditors with reports proving the data is archived/frozen.
- Prove to auditors that your data is restored.
- Have a reporting solution ready when auditors ask.
Data Compression
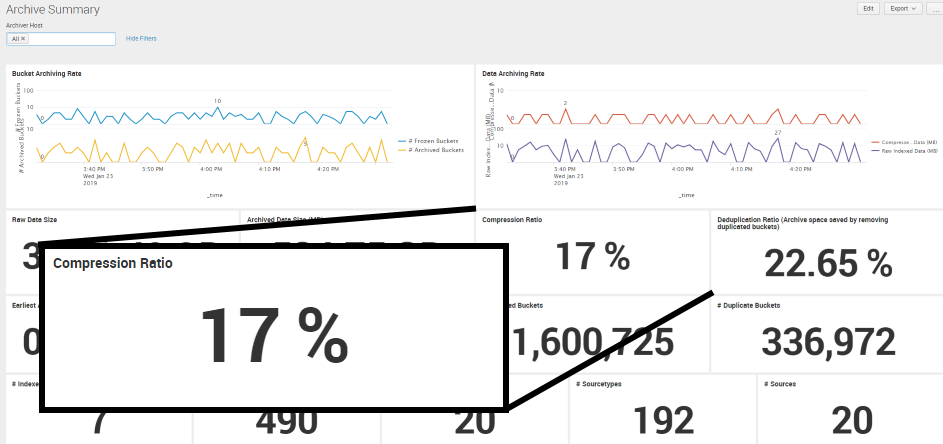
- Automatically compress data to about 20% of the original size.
- Reduce storage costs.

Encryption
- Once the data leaves Splunk, it remains encrypted throughout the entire process.
- Data is encrypted at rest and in flight.
Deduplicate Data
- Deduplicate buckets from clustered indexers. (A clustered indexing configuration will contain multiple copies of buckets.)
- Store only one copy of these buckets, saving time and money.
Cloud or On-Premises Storage
- The Archiver integrates with all major cloud storage providers, or you can choose to store locally.
- Content as low as $4 per TB per month.
Insights from Our Blog


5 Tips for Increasing Your Splunk ROI
Splunk is a powerful data analytics and visualization tool that can drive serious business results for its users by bringing real-time data insights into every decision in security, IT operations, and so much more.
Read More
Is Splunk a DIY option or do you need a professional partner?
Splunk has the power to be transformative but only if it’s implemented effectively. So, can you take the DIY route or should you be looking for a qualified Splunk partner?
Read MoreGet the most out of your operational intelligence solution today.
